

In diesem Beitrag bespricht unser CTO Benjamin Schiller einige überraschende Ergebnisse unserer neuesten Experimente zu Argument Mining und semantischer Suche. Dieser Beitrag ergänzt unsere Reihe zu LLMs und RAG (nach Teil 2 und Teil 1).
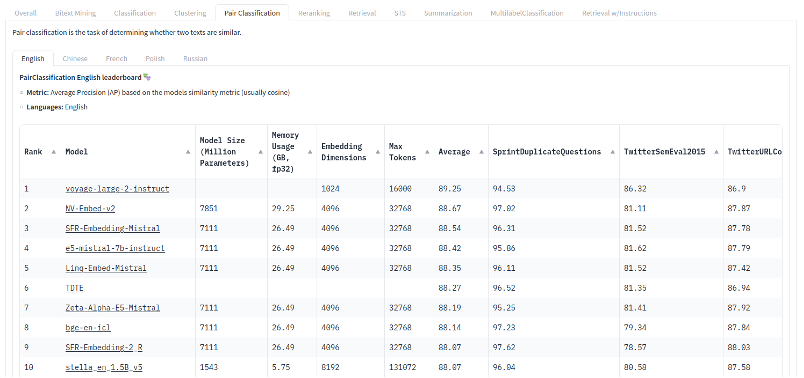
Wir haben kürzlich eine Reihe von Experimenten durchgeführt, die von Fortschritten im MTEB-Leaderboard inspiriert wurden. Die Ergebnisse waren überraschend. Keines der neueren, state of the art Modelle schnitt bei den domänenspezifischen Aufgaben, mit denen wir sie getestet haben (hauptsächlich Argument Mining), gut ab. Stattdessen sind einige der guten alten Modelle aus dem Jahr 2020 immer noch sehr wettbewerbsfähig – wenn nicht sogar besser.
Cross-Domain Experimente
Das klingt zwar kontraintuitiv, entspricht aber unseren Erfahrungen aus anderen LLM-Projekten. Dabei ist wichtig zu erwähnen, dass unsere Bewertungen streng domänenübergreifend sind. Das bedeutet, dass wir immer auf unterschiedlichen Quellen und Themen trainieren und testen. Wenn ein Modell beispielsweise darauf trainiert wird, politische Argumente in sozialen Medien zu identifizieren, testen wir dieses Modell auch auf Produktbewertungen. Modelle, die sich zu sehr auf bestimmte Themen (z. B. im Zusammenhang mit technischen Innovationen wie „künstliche Intelligenz“ usw.) oder bestimmte Datentypen (z. B. kurze Beiträge auf X/Twitter) konzentrieren, werden stärker bestraft als solche, die Präzision in einem einzelnen Thema/Bereich gegen breiteres, bereichsübergreifendes Wissen eintauschen. Selbst größere Modelle (mehr Parameter, mehr Trainingsdaten) sind nicht unbedingt besser für eine bereichsspezifische Aufgabe geeignet. Unserer Erfahrung nach sagen Fortschritte in den Bestenlisten oft nicht allzu viel über unsere internen Anwendungsfälle aus. Dies liegt daran, dass sie dazu neigen, sich zu sehr an die Bereiche und Aufgaben der jeweiligen Bestenlisten (in unserem Fall MTEB) anzupassen (zu „overfitten“).
Semantische Suche und Embeddings
Einen ähnlichen Effekt sehen wir bei der semantischen Suche. Semantische Suche ist stark abhängig von Embeddings ab, und Embeddings sind naturgemäß sehr domänenabhängig. Neuere Embeddings, die mehr Kontext einbeziehen, scheinen für dieses Problem noch anfälliger zu sein. Außerdem gehen Embeddings mit längeren Kontexten auf Kosten der Geschwindigkeit und Ressourcen. Komprimierung löst dieses Problem zu einem gewissen Grad, geht aber wiederum auf Kosten der Detailgenauigkeit, die für die Suche nach sehr spezifischen Themen erforderlich ist.[1] Letztendlich ist Standard-BM25 immer noch eine sehr starke Grundlage für viele Anwendungen (siehe auch Teil 2 dieser Serie).
Trotz aller beeindruckenden Fortschritte bei LLMs scheint es bei den meisten realen Anwendungen noch einige Herausforderungen beim Argument Mining und der semantischen Suche zu lösen zu geben. Wenn Sie wissen möchten, wie SUMMETIX die Herausforderungen der Kundenintelligenz und des Kundensupports mit Argument Mining und LLMs angeht, senden Sie uns eine LinkedIn-Nachricht oder füllen Sie das Formular auf unserer Website aus.
[1] Wenn Sie sich eingehender mit diesem Thema befassen möchten, empfehlen wir Ihnen diese Folge des Podcasts „How AI is Built“ mit unserem ehemaligen UKP-Lab-Kollegen Nils Reimers.

